Mysql如何实现事务
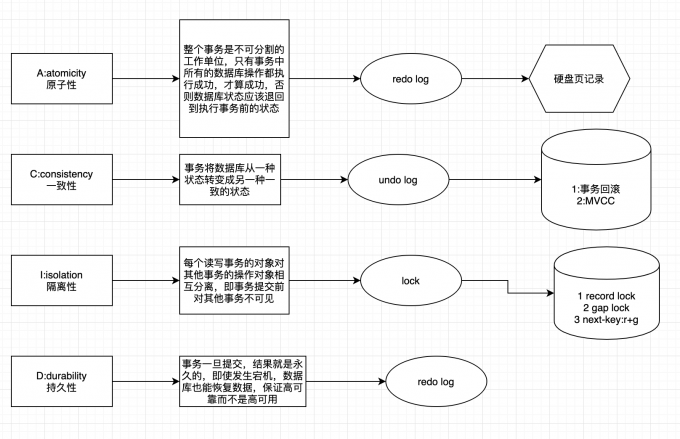
这是一个很大的问题。可以从事务的ACID特性的四个角度来分析。 D(durable 持久化)最简单。redo log
原子性:由undo保证; 持久性:由redo保证; 隔离性:由undo+事务ID+mvcc保证; 一致性:由程序保障+AID,一致性是我们最终的目的。
undo log && MVCC
事务隔离是怎么通过read-view(读视图)实现的? 每一行数有多个版本,当我们要去读取数据的时候,要判断这个数据的版本号,对当前事务而言,是否可见,如果不可见,则要根据undolog计算得到上一个版本。如果上一个版本也不符合要求,则要找到再上一个版本, 直到找到对应正确的数据版本。
并发版本控制(MCVV)的概念是什么, 是怎么实现的? 并不是数据版本比当前事务的ID大,对当前事务来说,此版本的数据不可见了。因为事务启动(begin)的时候就分配了事务ID,但是一致性视图是在第一个快照读的时候才创建的,如果在这段时间内(启动事务和一致性视图创建间隔),有其他事务开启并提交了,对于当前事务来说这些提交依然是可见的,即使这些事务ID比当前事务的ID大
使用长事务的弊病? 为什么使用常事务可能拖垮整个库? 长事务导致表空间持续增长,即便是事务提交或者回滚后,回滚表空间被是否后,表空间大小仍然不会被缩小。 长事务的存在导致锁发生冲突或等待的几率大大增加。 如果某个应用有发生锁等待后尝试重新建立连接的机制,那么在发生锁等待或冲突的时候,应用就会不断地发起新的连接,导致MySQL的连接数被占用爆满。MySQL不能在提供连接服务,就挂掉了。
连接池的公平锁与非公平锁
// 设置druid 连接池非公平锁模式
dataSource.setUseUnfairLock(true);
公平锁影响性能,于是将改为非公平锁模式,其实 druid 默认配置为非公平锁,不过一旦设置了maxWait 之后就会使用公平锁模式。在只修改一个参数的请求下,单机性能提升接近一倍,集群的吞吐量也差不多提升 70%。不过公平锁与非公平锁有这么大的性能差距还是比较震惊的。使用 HikariCP 替换后发现效果还是非常不错,单机性能一下从 1.5k(druid 公平锁) 提升到接近 3k.
还有一个小插曲是顺便调研了数据库连接池 HikariCP(https://github.com/brettwooldridge/HikariCP) ,使用 HikariCP 替换后发现效果还是非常不错,单机性能一下从 1.5k(druid 公平锁) 提升到接近 3k。其实 HikariCP 的一个优势就是快,当时都想要在公司推一波,不过要整个公司替换一遍也是不小的动作,虽然连接池使用上两者十分接近,但是配套的监控要重新弄一遍还是比较劳民伤财的。还好最终测试发现大部分情况下 druid 还不至于成为服务的瓶颈,而且配套的监控也比较全,如果真的追求更高的性能,HikariCP 是一个不错的选择。
有赞案例参考:
https://tech.youzan.com/you-zan-shu-ju-ku-lian-jie-chi-xing-neng-you-hua/
https://database.51cto.com/art/202101/641019.htm https://blog.csdn.net/SnailMann/article/details/94724197 https://www.zhihu.com/question/370950509/answer/1958141987
Is this article useful to you? How about buy me a coffee ☕ ?